



Most IT teams hit a wall around 30 to 40 hires per month. After that, manual onboarding either burns out the team or breaks the new-hire experience. Headcount won't fix it. A different operating model will.
We've watched lean IT teams handle 100+ monthly hires without growing. The pattern holds across companies, industries, and country mixes, and it comes down to five shifts.
This piece walks through each one: the operating principle behind it and what changes in practice. It's written for IT Operations leaders running between 250 and 5,000 employees who can already feel the wall coming.
1. The HRIS becomes the trigger, not a Teams message
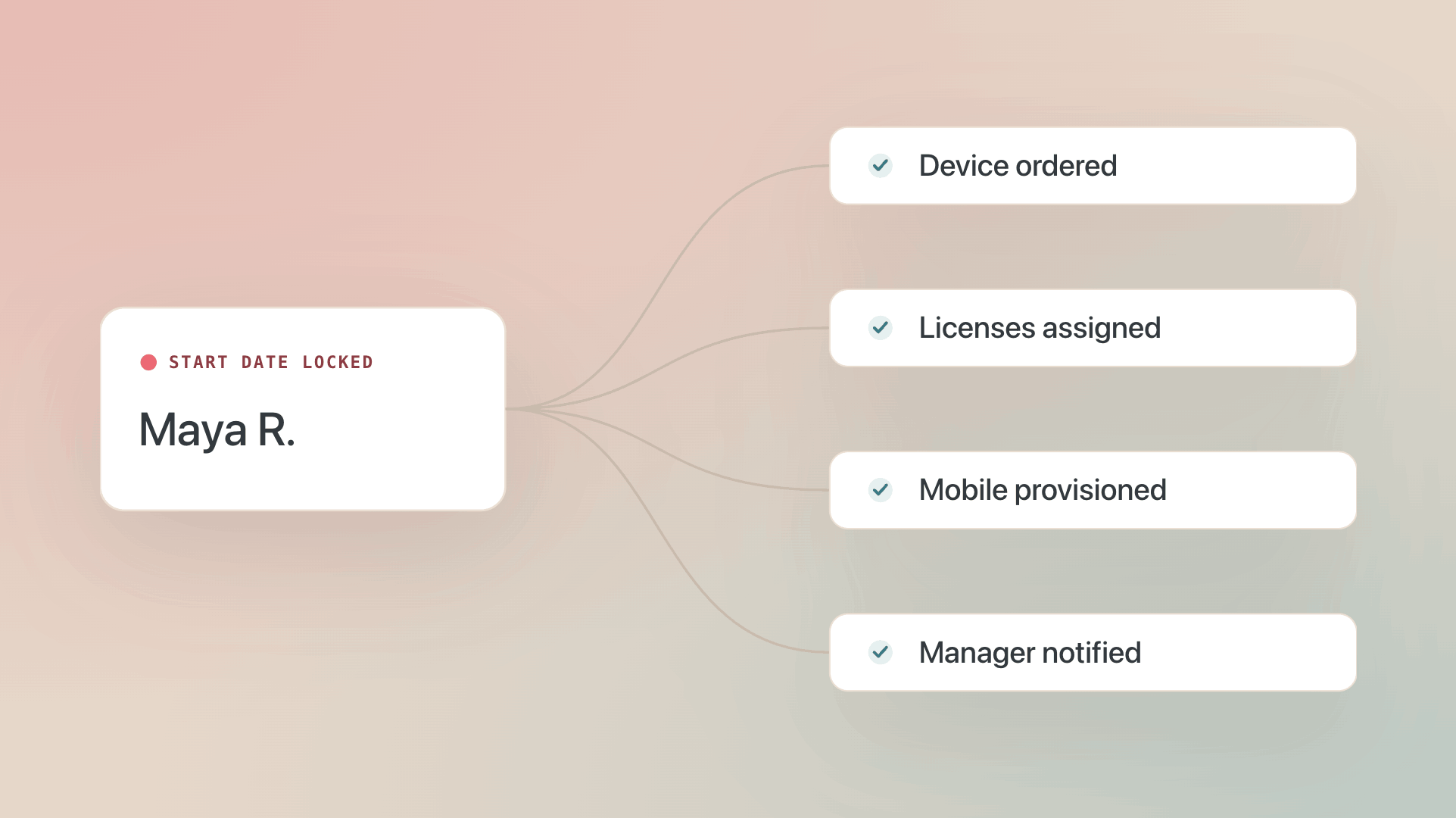
When onboarding lives in Teams, every hire is a fresh conversation. Someone from HR drops a heads-up on Tuesday, IT spins up a ticket, the laptop gets ordered Thursday, and the new hire's start date passes with their device still en route.
When onboarding lives in the HRIS, the trigger fires automatically the moment the start date is locked. Device order, license assignment, mobile plan provisioning, and manager notification all kick off from the same source of truth.
The shift sounds small, but in practice it removes the most failure-prone link in the chain: the human handoff between HR and IT. It's usually the single biggest time-saver of the five.
The teams that scale past 30 hires per month don't add headcount. They build a system that doesn't wait to be told.
2. Role-based bundles get defined once, not per hire
Per-hire customization is what quietly eats IT capacity. Every "can we add a Hubspot seat for this one?" conversation is small on its own and crushing in aggregate.
The fix is a role-bundle model: a handful of standard kits, usually fewer than a dozen, that cover the large majority of hires. A bundle is a named package: laptop class, peripheral set, license stack, mobile plan. New developers get the Engineering bundle. New AEs get the Sales bundle. New operations hires get the Ops bundle.
The hires who fall outside the bundles still get bespoke handling, but those exceptions are now visible. They go through an exception flow that captures why, who approved it, and whether the bundle should be updated.
The exception process matters as much as the bundles themselves. Skip it and the bundles drift out of date; keep it and they stay accurate while exceptions stop becoming the norm.

3. Approval flows route on rules, not on memory
When approvals live in someone's head ("for hardware over 30K EUR, ask Pia"), they break the moment that person is unavailable, transitions out, or gets too busy. They also break compliance: there's no audit trail.
Rule-based approval workflows fix both. The system routes the approval based on the request, not on memory. Anything within the company budget can be approved automatically; anything above it pings the attestation manager, which can be the line manager, IT, or whoever your rules say. Every approval is logged with timestamp, approver, and rationale. When auditors show up, the data is already there.
The teams that scale to 100 hires per month treat approvals as plumbing, not as decisions.
4. Managers get self-service for everything that doesn't need IT
The Voyado model is worth studying: managers shop the store, IT runs the engine. New hire needs an extra monitor? The manager orders it from the catalog. Someone changing roles needs different software? The manager submits the request through a self-service flow.
What stays with IT is the engine itself: the bundles, the policies, the supplier relationships, the integration health, the lifecycle decisions. What moves to managers is the day-to-day requests that used to fill IT's queue.
The trade-off teams worry about is governance. If managers can order things, won't spend run wild?
It doesn't, as long as the self-service is bounded by approved bundles, budget rules, and approval thresholds. Managers can shop within the catalog. They can't add new vendors, exceed the budget, or skip the approval flow. The freedom is real, and so are the rails. And if you want to take it a step further, you can let employees manage their own procurement in the self-service store.
When self-service ships, most of the volume that drops is simple requests that never needed IT judgment in the first place. The tickets that remain are the ones that actually do.
5. Day-1 readiness becomes a single metric
"Average time to laptop" is a misleading metric because the average hides the failures.
Day-1 readiness is binary: did the new hire have everything they needed on their first day, yes or no? It tracks per hire. Anything less than 100% is a failure that gets investigated.
This metric forces the right behavior. It can't be gamed by an above-average week. It surfaces the edge cases: the contractor who got skipped, the international hire with a country setup gap, the role change that didn't trigger. It gives the IT team something concrete to optimize against.
Once the metric is binary, the conversation changes, from "how fast did we onboard people on average" to "which specific hires had a Day-1 failure, and why." That's a far more useful conversation.
What it looks like when these five shifts are running
A 5-person IT team handling 100 hires per month doesn't feel busier than a 5-person team handling 20. The difference is what they're working on.
Manual provisioning shrinks to exception handling. Bundle and policy work becomes the recurring focus. The team has time to scope strategic projects like refresh planning, vendor consolidation, and security posture, because the operational work is running itself.
The honest version: most of this is live within weeks, not months, once the HRIS connection is in place. The rest is workflow design, not engineering.
And if your IT team is hitting the 30-hire wall right now, the order matters. HRIS connection first, role bundles second, approval routing third, manager or employee self-service fourth, Day-1 metric last. Each one builds on the previous, and skipping ahead usually means the foundation isn't strong enough to support the speed.
What this actually is
This is about treating onboarding as a workflow instead of a series of judgment calls. Not working faster, not cutting corners on security or compliance, and not hiring your way out of the volume.
The teams that scale past 100 hires per month built the plumbing. The ones that don't are still treating every hire as a fresh problem.
If you're hitting the 30-hire wall, book a call with our team. We'll walk through where the bottleneck is in your setup and what the first connector would unlock.


